(토요일)
적어야 할 다이어리가 바로 떴다… 다사다난한 주말…
토요일… 카메라 때문에 노트북과 데스크탑을 동시에 사용하기가 싫어서 웹캠을 샀습니다.
웹캠 받자마자 너무 맘에 들어서 만져보고 테스트 해보니 마이크 소리가 좀 작은 것 같아서 유튜브 보면서 부스트 프로그램을 사용하기로 했어요!! (정말 하지 말았어야 했어…)

내 컴퓨터가 랜섬웨어의 공격을 받았습니다… 일부 파일 형식이 알 수 없는 확장자로 변환되어 차단되었습니다. 티^티
운영 체제를 다시 설치하는 데 필요한 프로그램을 좋은 파일 선택, 백업, 포맷, 복원 및 설치하기 위해 태그가 지워졌습니다.
(낮)

오랜만에 요리를 해보는 자세로 칼을 뽑아 소시지인 줄 알고 손을 잘랐다.
내 인생에서 처음으로 구급차 내부를 보았습니다. (생각보다 아늑했어요)
항해를 시작한 직후 이것저것을 머릿속에 집어넣으면서 이런 일들이 연달아 일어나서 그런 것인지…
아니면 분당 어디선가 불어오는 쌀쌀한 밤바람에 반팔 티셔츠+집업 후드티에 슬리퍼 신고…
나는 거의 내 마음을 아프게했다 …
하지만!!! 그래서 올해 모든 트릭을 수행하고 다시 걷기 시작했습니다!!!
불만 사항이 있습니다.
미리 고백할게, 오늘은 알고리즘 문제도 만지지 못했는데…
1. 다리
https://www.acmicpc.net/problem/1010
1010호: 교량 건설
테스트 케이스의 수 T는 첫 번째 입력 라인에 지정됩니다. 다음 줄부터 강의 서쪽과 동쪽에 있는 위치 수의 정수 N과 M(0 < N ≤ M < 30)이 각 테스트 케이스에 대해 제공됩니다.
www.acmicpc.net
2. 피보나치 함수
https://www.acmicpc.net/problem/1003
라인 1003: 피보나치 함수
각 테스트 케이스에 대해 0의 출력 수와 1의 출력 수가 공백으로 구분되어 인쇄됩니다.
www.acmicpc.net
3. 평범한 배낭
https://www.acmicpc.net/problem/12865
12865호: 심플 백팩
항목 수 N(1 ≤ N ≤ 100)과 기준이 견딜 수 있는 무게 K(1 ≤ K ≤ 100,000)는 첫 번째 줄에 표시됩니다. 2행부터 N행까지 각 물체의 가중치 W(1 ≤ W ≤ 100,000)와 물체의 값 V(0 ≤ V ≤ 1,000)
www.acmicpc.net
문제를 훑어본 후 오늘의 요점 동적 프로그래밍(DP) 개념을 이해하려고 구글링을 했다고 하는데 DP를 이해하려면 배경이 먼저 준비되어야 할 것 같아서 오늘 강의에 집중하기로 했습니다.
알고리즘이란 무엇입니까?
– 문제를 해결하기 위한 순차적인 (계산/해법) (절차/방법)의 집합, 즉 문제를 해결하는 과정.

코딩을 하는 우리들에게 Big O 표기법이 훨씬 더 중요합니다. (빅 오메가 표기법 <<<< 빅오 표기법)
문제를 푸는 동안 코드의 최악의 성능을 예상하면서 코드를 작성해야 하기 때문입니다!

물론 공간복잡도를 고려하는 것도 중요하지만 프로그램의 처리속도가 우선한다고 합니다.
다음 문제를 보면서 알아봅시다.
https://www.acmicpc.net/problem/10809
#10809 알파벳 찾기
각 알파벳에 대해 a가 처음 나타나는 위치, b가 처음 나타나는 위치, … z가 처음 나타나는 위치가 공백으로 구분되어 인쇄됩니다. 단어에 알파벳이 없으면 -1을 출력합니다.
www.acmicpc.net

문제에 대한 이해
1. 먼저 사용자가 입력으로 단어를 입력합니다.
2. 입력된 단어를 구성하는 문자(A~Z)와 해당 단어에서 각 문자의 위치가 출력됩니다.
문제에 대한 해결책
1. 임의의 변수 S에 단어가 입력됩니다.
2. 단어에 (A to Z)가 나오는지 확인하세요.
3. 알파벳이 존재한다면 단어에 어떤 index()가 있는지 확인합니다.
4. 해당 값을 빈 리스트에 저장하고, join()으로 출력 형식에 따라 변환하여 출력합니다.
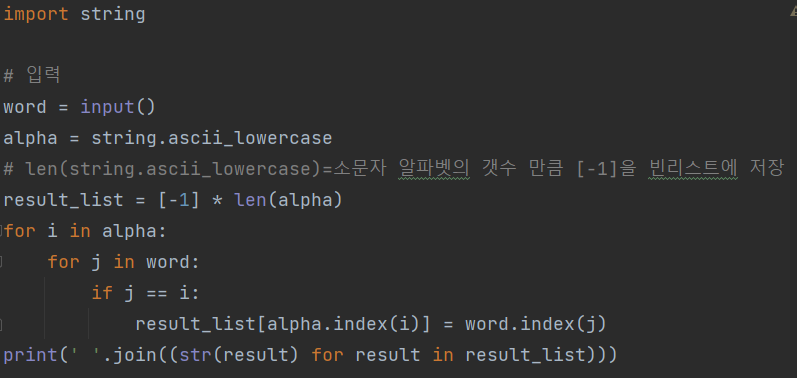
# 이중 for 문 해결
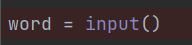

입력 단어와 비교할 알파벳은 alpha라는 변수에 저장됩니다.
string.ascii_lowercase를 사용하면 A에서 Z까지의 알파벳을 소문자로 얻을 수 있습니다.
result_list = (-1) * len(alpha) => -1(int)는 왼쪽 리스트에 알파벳 개수만큼 저장된다.
(-1, -1, -1, -1, -1, … , -1, -1)로 저장된다.

입력한 단어와 알파벳을 비교하여 같으면 해당 단어의 인덱스 값을 목록의 알파벳 인덱스에 저장합니다.

문법을 접하는 건 처음이라 조금 어렵네요. 해결하자
문자열(결과) ~을 위한 결과 ~ 안에 result_list => result_list의 요소를 하나씩 가져 와서 result 변수에 삽입하고 문자열로 변환합니다.
예를 들어 백준을 입력하면
(‘2’, ‘0’, ‘-1’, ‘-1’, ‘1’, ‘-1’, ‘-1’, ‘-1’, ‘-1’, ‘4’, ‘3’ , ‘-1’, ‘-1’, ‘7’, ‘5’, ‘-1’, ‘-1’, ‘-1’, ‘-1’, ‘-1’, ‘-1’, ‘ -1’, ‘-1’, ‘-1’, ‘-1’, ‘-1’).
마지막으로 ‘ ‘.join()에 해당 값(목록)을 넣으면 각 요소 사이에 ‘ ‘가 추가됩니다.
인쇄
전체 코드
# ASCII 코드 풀기
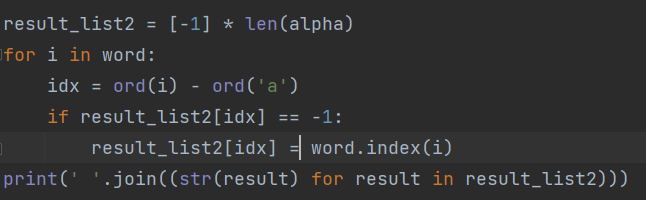

ord() 함수는 수신된 문자의 ASCII 코드 값을 요소로 반환합니다.
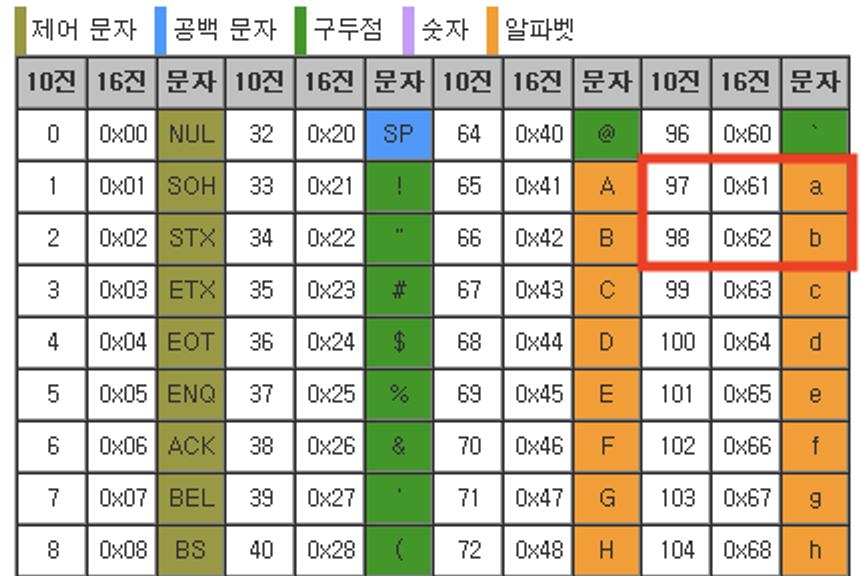
이때 알파벳의 경우 소문자와 대문자의 반환 값이 다르므로 주의하세요!
여기서 ord(i) – ord(‘a’)는 적어도 0~25의 값이다. 즉, 알파벳을 나열하여 저장되는 result_list2의 인덱스 값이다.
해당 인덱스의 값이 -1이면 값이 비어있으므로 해당 인덱스에 word.index(i)가 저장된다.
나머지는 위와 같습니다.
차이점
위의 알파벳 찾기 문제는 두 가지 방법으로 해결되었습니다.
시간 복잡도 측면에서 두 솔루션을 비교하면 위의 double for 문을 사용하면 최대 26 * 입력 단어 길이의 시간 복잡도가 있습니다. 다시 말해서. 입력 단어가 길수록 해당 코드를 처리하는 데 더 오래 걸립니다.
그리고 물론 다음과 같은 ASCII 코드로 솔루션을 보면 ASCII 코드라는 것을 알고 있어야만 접근 가능한 방법입니다.
for 문이 두 번 사용되고 for i 는 단어의 길이만 반복되므로 위의 코드보다 시간복잡도가 훨씬 간결해진다.
이와 같이 앞으로 발생할 알고리즘 문제를 풀 때 단순히 문제 풀이에만 집중하기보다 시간복잡도 측면에서 보다 효율적인 알고리즘이 되기 위해 어떻게 접근해야 할지 고민하면서 해결해야 한다. 문제.
끝…
현재 Excel 스프레드시트에 제시된 문제는 해결되지 않았습니다. 아마 내일도 그럴 것이다.
다른 멤버들이 하나 둘씩 멀어지고 나와의 거리가 멀어져가며 긴장했던 하루였다.
하지만 오늘 레퍼런스의 기반을 다졌으니 알고리즘에 대한 좀 더 효율적인 접근이 가능하리라 믿습니다!!